Often the monitoring tools organizations use simply don't work in the complex ecosystem of microservices and for technologies like Kubernetes.
Finding the root cause of problems is harder than ever before and the effort required goes beyond what is humanly possible when the application spans to the cloud providers and data centers and the explosion of interconnected services. There are more possibilities for failures and more hiding spots for problems to sneak into the environment when software driving more than just the application.
In this lab, we will trigger a few problem and see how troubleshooting time is significantly reduced by letting AI automatically detect problems and pinpoints the root cause, explaining business impact with no manual configurations.
Objectives of this Lab
🔷 Enable a problem in the application and walk through what Dynatrace Davis found
The Dynatrace Orders sample application has pre-built problems with different versions.
These problems can be enabled with a setversion URL that can be used to change the version and thus the behavior of the application. Version 1 is the "normal" behavior and problems are enabled by setting the version to a value such as 2 or 3.
In the next section, you will run a unix script that sets these problems.
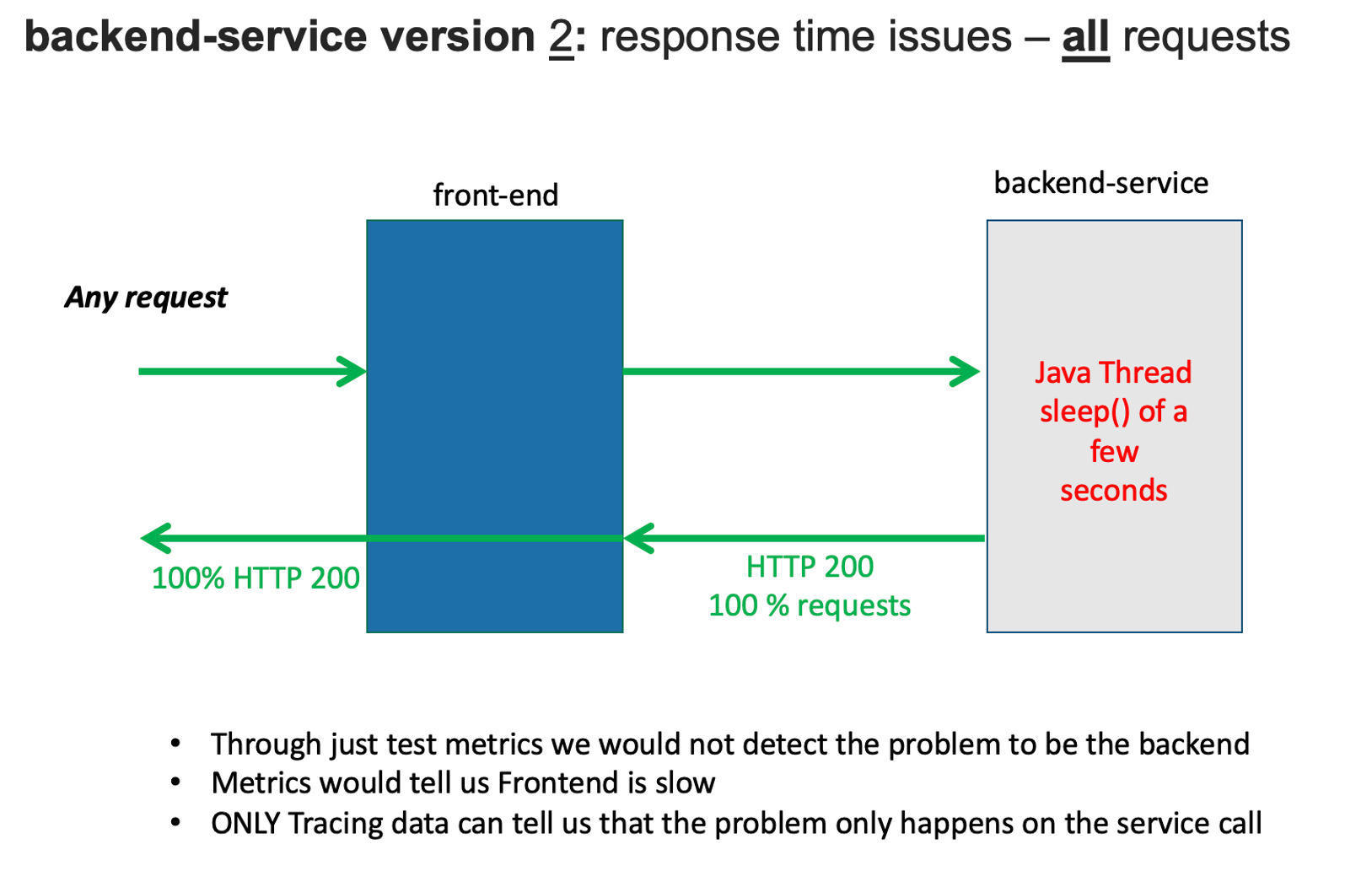
Monolith deployment - backend service - High Response time for all requests
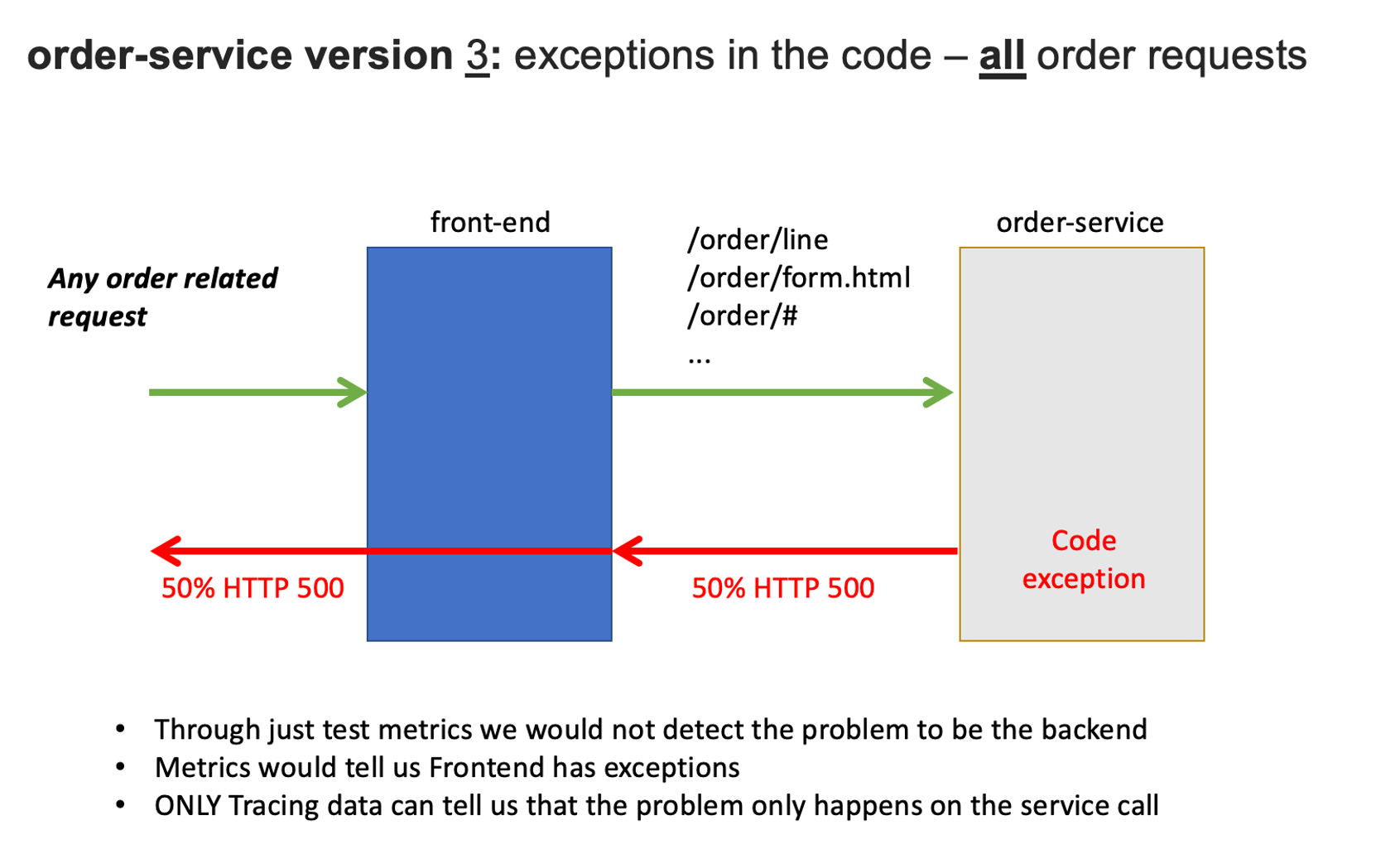
Service deployment - order service - exceptions for all order related requests
💥 TECHNICAL NOTE
Refer to dt-orders overview README
Before we get to the problems, let's review Refer to Dynatrace information events.
Dynatrace information events enable continuous delivery tools to provide additional details for Dynatrace. Here is an example of two informational events for deployment and performance testing being be sent to Dynatrace.

There are several Dynatrace information event types:
CUSTOM_ANNOTATIONCUSTOM_CONFIGURATIONCUSTOM_DEPLOYMENTCUSTOM_INFOMARKED_FOR_TERMINATION
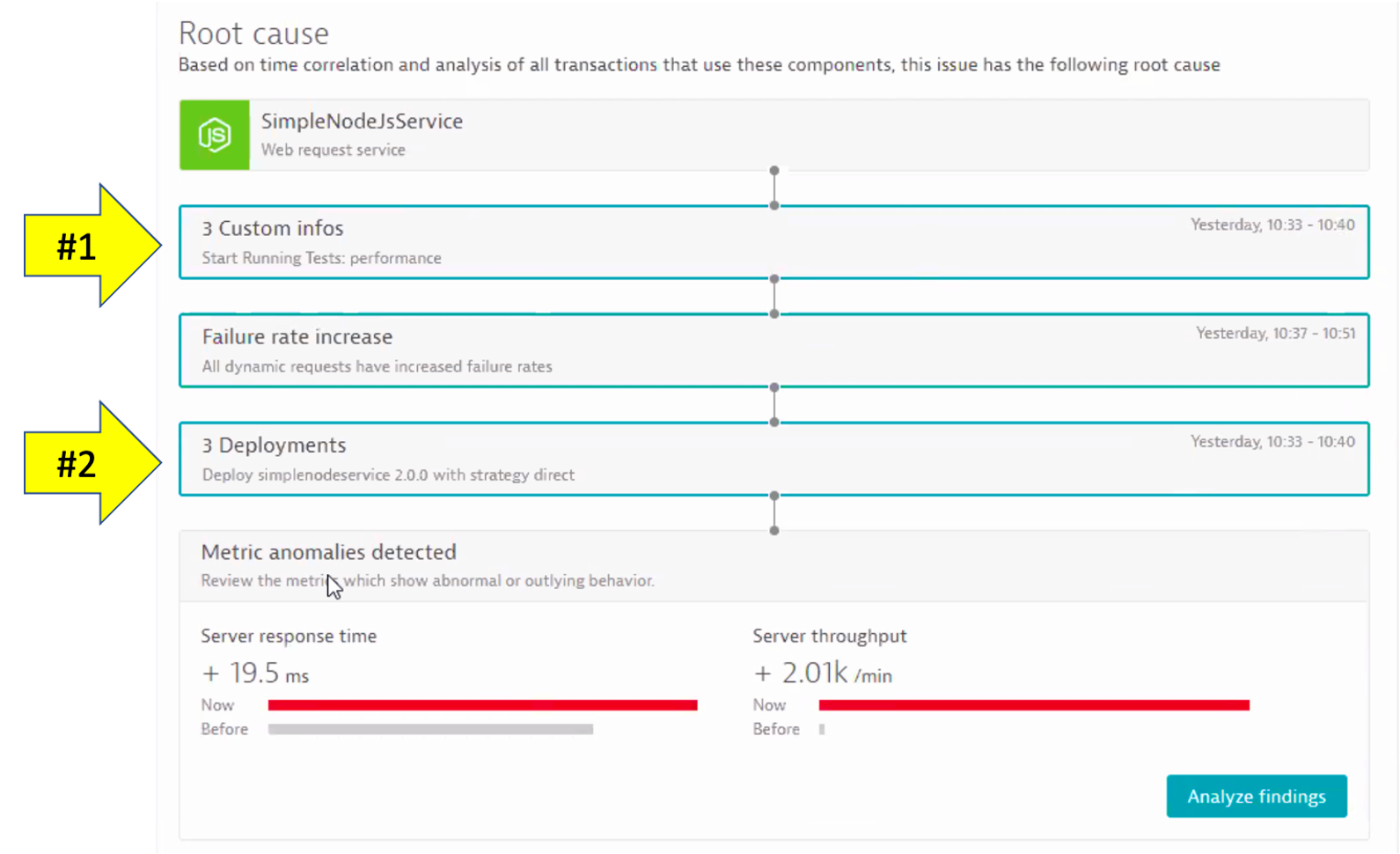
Below we can see for a service that was the root cause to a problem the Dynatrace AI engine, Davis®, determined:
- (#1)
CUSTOM_INFOevents and - (#2)
CUSTOM_DEPLOYMENTevents
Each event has a timestamp, event source, a few standardized fields (depending on the event type), and the option to add additional custom fields. See this table for details.
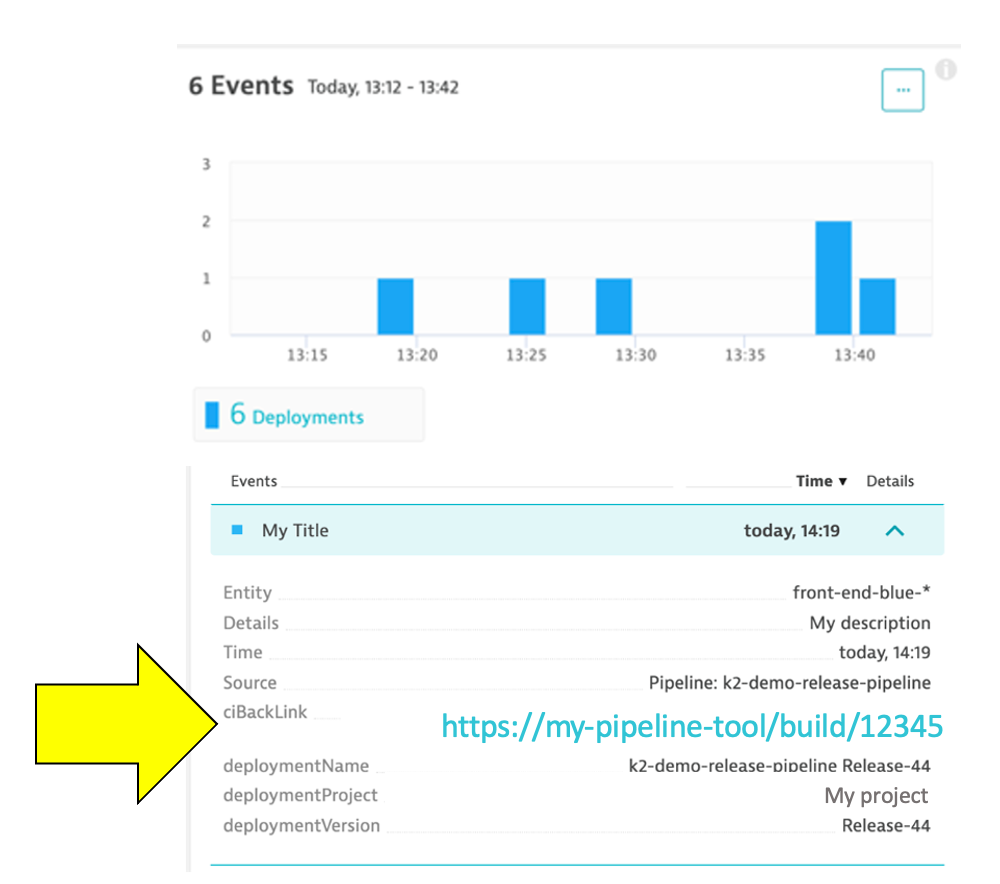
Here are two example events. NOTE the URL back to the pipeline making the change.
👍 How this helps
Having information events speeds up triage by adding context to what's happening with the application. Just imagine getting alerted about an issue and immediately seeing a load test or deployment took place, and in one click of the event, URL review the system, job, and team responsible!
Dynatrace tags
When creating information events, you must target the entities to receive the event so that it's only associated with the relevant component. That is where Dynatrace tags come in.
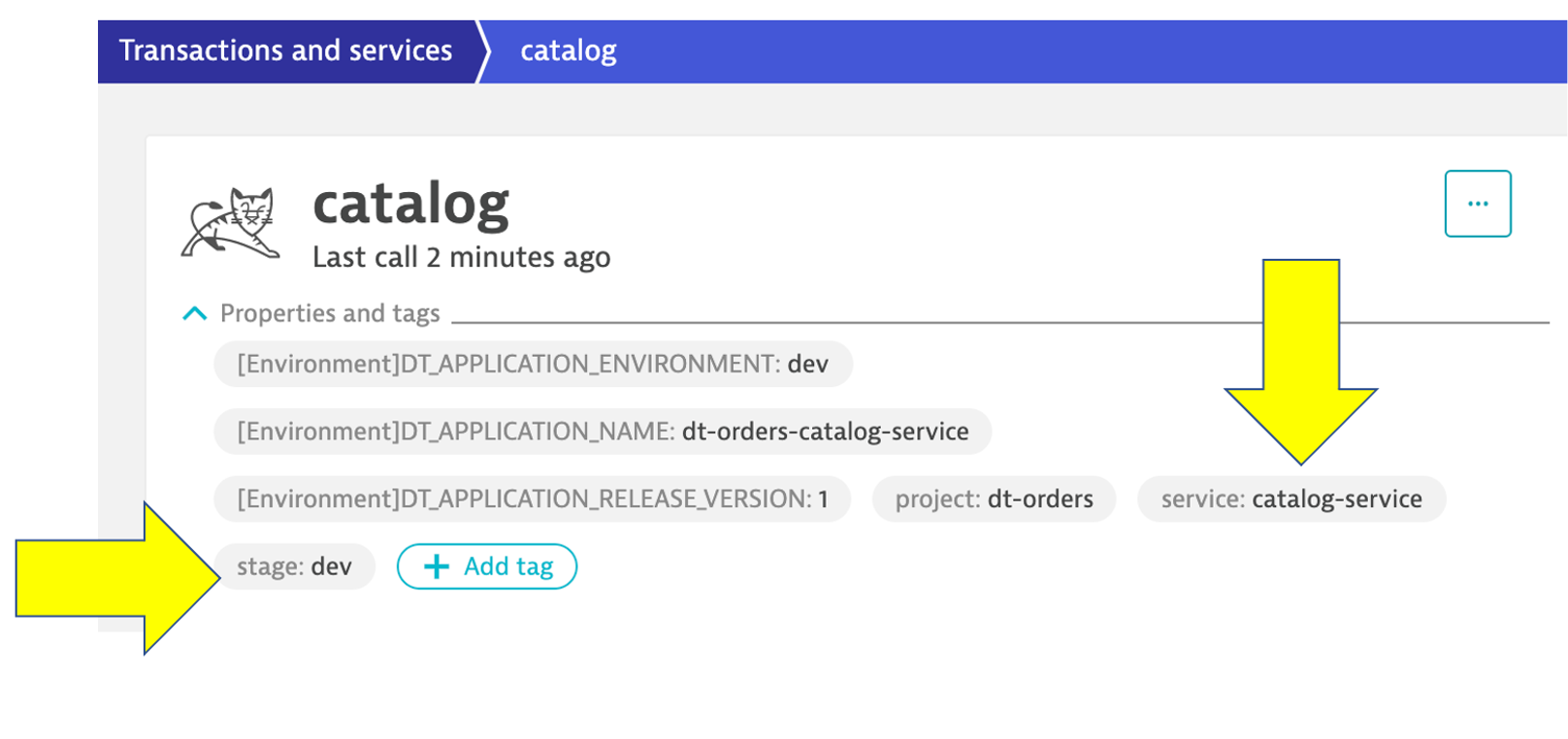
In a nutshell, tags in Dynatrace are labels or markers used for organizing entities in large monitoring environments. Below shows a few tags for my catalog service: stage:staging and service:catalog-service
API call Example
Here is an example of a typical events API call. You do not need to executed this as you will see this in action as part of the scripts in the next step
curl -X POST \
https://mySampleEnv.live.dynatrace.com/api/v1/events \
-H 'Authorization: Api-token abcdefjhij1234567890' \
-H 'Content-Type: application/json' \
-d '{
"eventType" : "CUSTOM_DEPLOYMENT",
"source" : "Pipeline Script" ,
"deploymentName" : "Set order-service to version 1",
"deploymentVersion" : "1" ,
"deploymentProject" : "dt-orders project" ,
"ciBackLink" : "http://link-back-to-my-pipeline",
"customProperties": {
"Example Custom Property 1" : "Example: Commit SHA",
"Example Custom Property 2" : "Example: Name of person who run pipeline",
"Example Custom Property 3" : "Example: Application owner name",
"Example Custom Property 4" : "Example: Ticket Number approving change"
},
"attachRules": {
"tagRule" : [
{
"meTypes":["PROCESS_GROUP_INSTANCE"],
"tags": [
{
"context": "CONTEXTLESS",
"key": "service",
"value": "order-service"
},
{
"context": "CONTEXTLESS",
"key": "project",
"value": "dt-orders"
},
{
"context": "CONTEXTLESS",
"key": "stage",
"value": "production"
}
]}
]}
}
}'
Now we are going to set the backend service version that will cause high response time for all backend requests.
To automate the version change, a unix script is provided that will do the following:
- Call the
backend/setversionURL set the backend version - Send a Dynatrace
CUSTOM_DEPLOYMENTevent indicating the change
After a minute or so, you should expect to see high Response time for all requests.
1. Enable the problem pattern
From the AWS CLoudShell, run these commands to set the backend service to version 2
cd ~/aws-modernization-dt-orders-setup/learner-scripts/
./set-version.sh backend 2
Review the output to ensure the change was made successfully. I should look like this with numerical values at the end for Response Data: storedEventIds:
Retrieving dt-orders-monolith Public IP
=================================================================
Setting Service Version
SERVICE = backend
NEW_VERSION = 2
SET_VERSION_URL = http://1.1.1.1/backend/setversion/2
=================================================================
Set backend to 2 was successful
=================================================================
Sending Dynatrace Deployment event
DT_API_URL = https://xxx.live.dynatrace.com/api/v1/events
DEPLOYMENT_NAME = Set backend to version 2
DEPLOYMENT_VERSION = 2
DEPLOYMENT_PROJECT = dt-orders
CI_BACK_LINK = http://1.1.1.1
=================================================================
Push Event POST_DATA
{ "eventType" : "CUSTOM_DEPLOYMENT", "source" : "Custom Unix Shell Script" , "deploymentName" : "Set backend to version 2", "deploymentVersion" : "2" , "deploymentProject" :"dt-orders" , "ciBackLink" : "http://1.1.1.1", "customProperties": { "Example Custom Property 1" : "Example Custom Value 1", "Example Custom Property 2" : "Example Custom Value 2", "Example Custom Property 3" : "Example Custom Value 3" }, "attachRules" : { "tagRule" : [ { "meTypes":["PROCESS_GROUP_INSTANCE"], "tags": [ { "context": "CONTEXTLESS", "key": "service", "value": "backend" }, { "context": "CONTEXTLESS", "key": "project", "value": "dt-orders" }, { "context": "CONTEXTLESS", "key": "stage", "value": "production" } ]} ]} } }
Response Data
{"storedEventIds":[8663164135574257870,-5988376401319068441],"storedIds":["8663164135574257870_1628095127627","-5988376401319068441_1628095127627"],"storedCorrelationIds":[]}
2. View app in browser
The event has the URL back to the sample application, so just click that if you don't have the sample app up already. You should see version 2 for the customer app now too.

3. Review problem in Dynatrace
The problem may take a minute to show up, but this is what the problem will look like once it does.
To view Dynatrace problem cards, from the Dynatrace left side menu just navigate to Problems.
NOTE: Be sure that your management zone is NOT filtered!
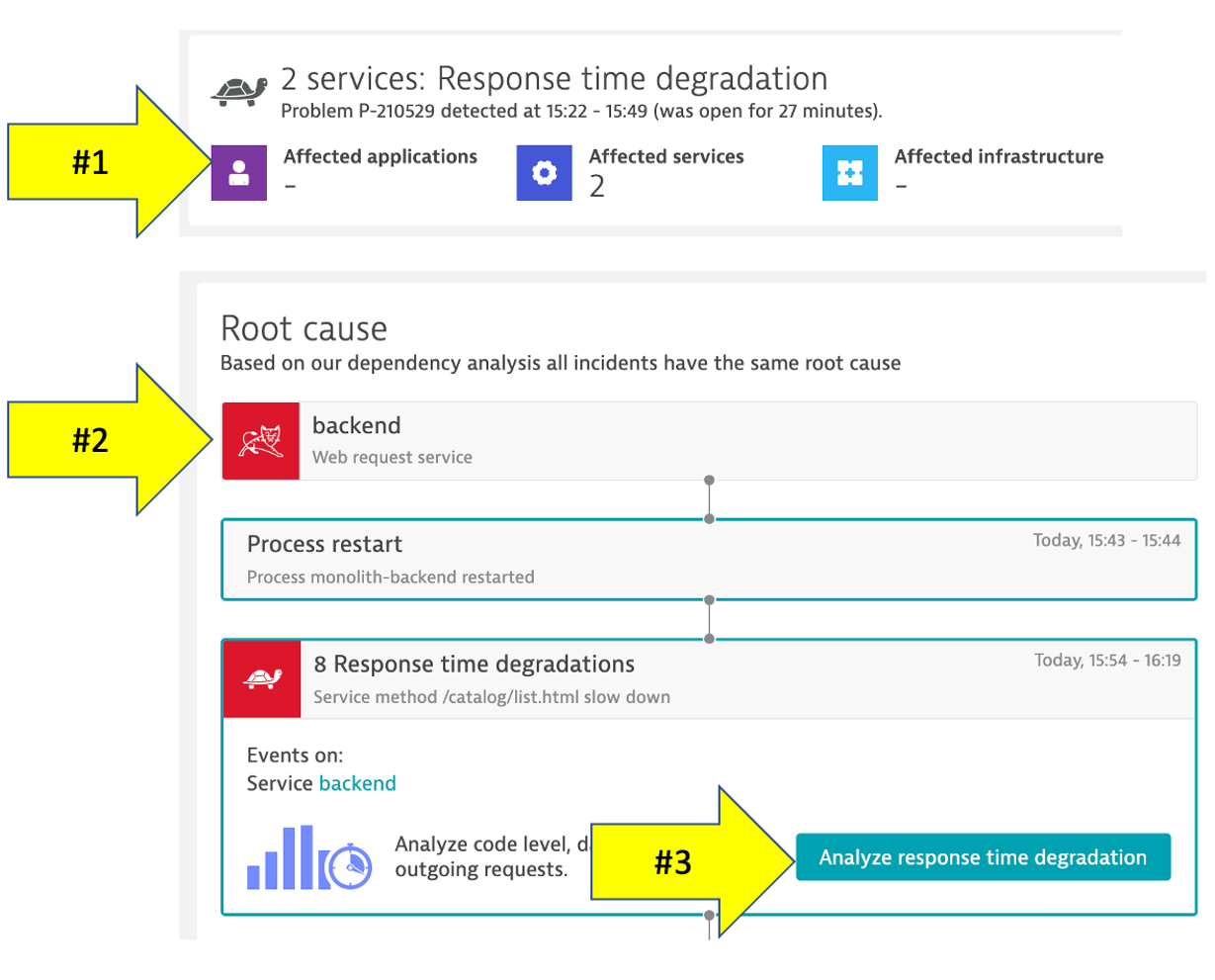
You may see two problems that eventually get merged into one as Dynatrace is performing the problem analysis.
- Impact Summary - Multiple services affected
- Root cause
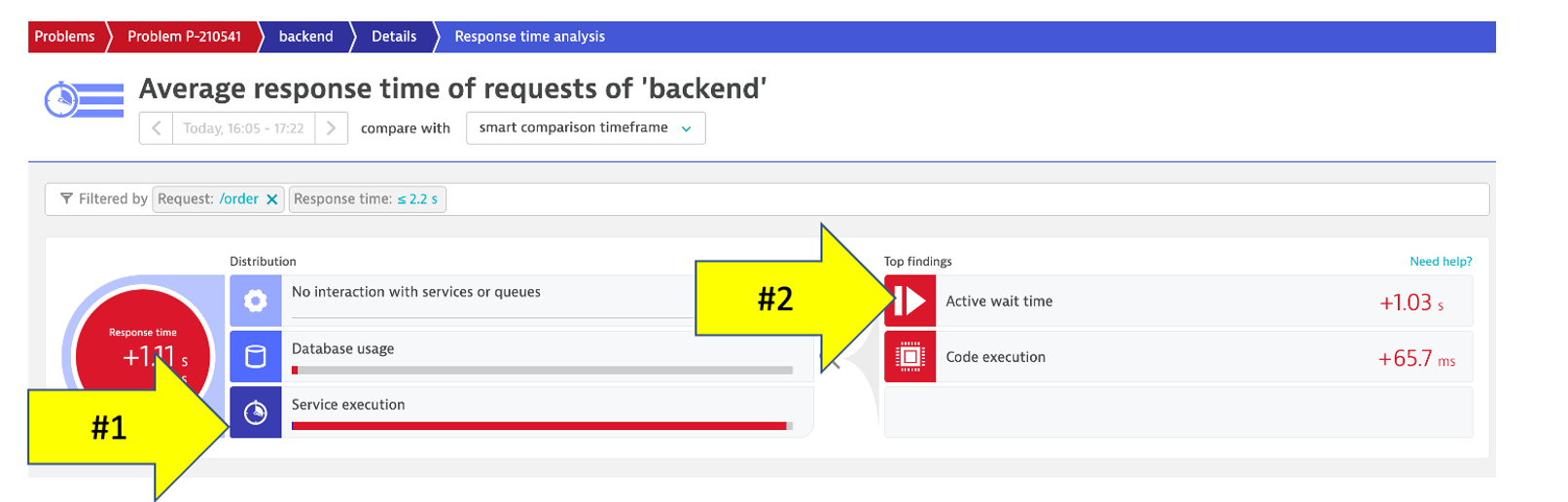
4. Analyze problem - top findings
Click on the Analyze Response Time Degradation button to view the real issue with the request. To open the top findings page.
Here you can see how Dynatrace automatically analyzes the problem and lets you know whether the problem is related to code, waiting, or other services and queues.
Click in the active wait time line with the top findings to open the execution time breakdown detail.
5. Analyze problem - execution time breakdown
Dynatrace automatically show the breakdown of the execution time. To see more, click the View method hotspots button.
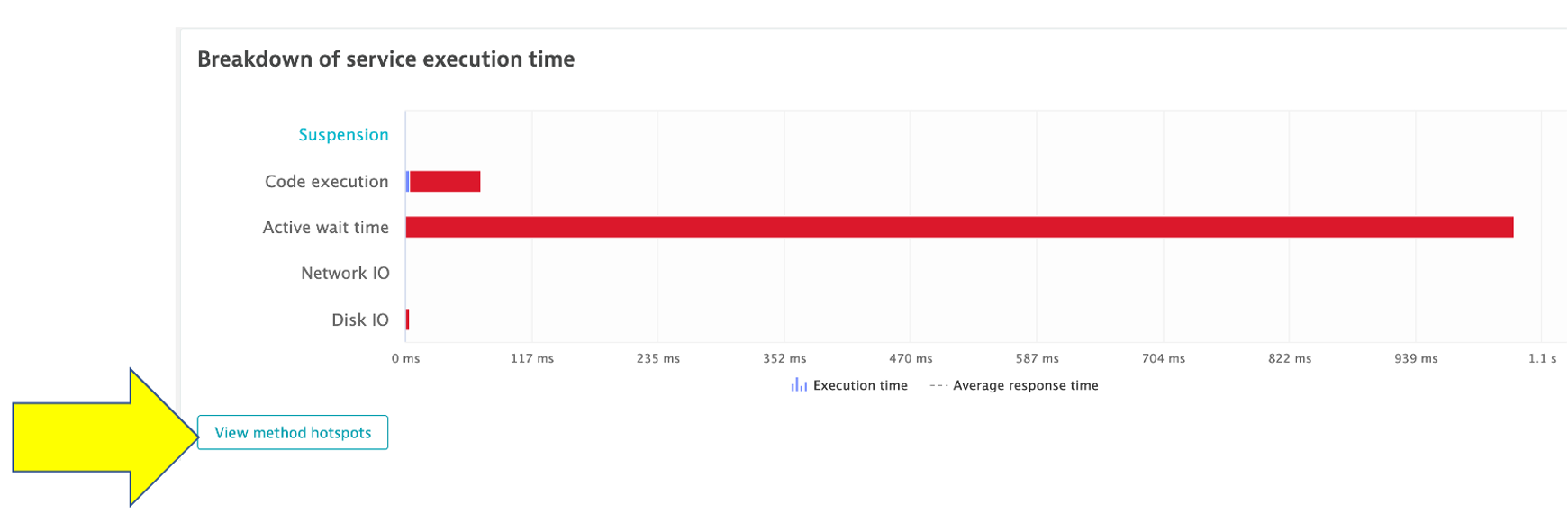
6. Analyze problem - hot spots
Here the code call breakdown is shown and by expanding this tree, you can locate the method where the slow down is occurring. NOTE: You will need to expand several stack frames to get to method causing the slow down.
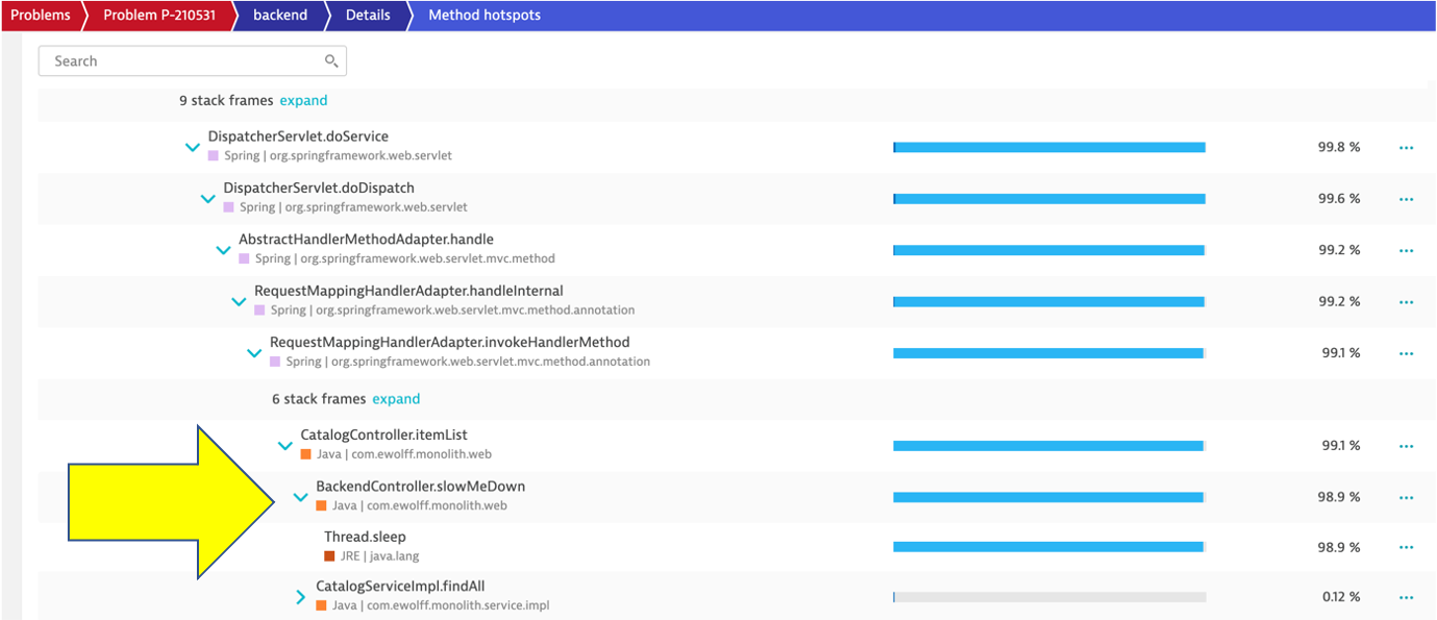
7. Analyze problem impact
From the breadcrumb menu, click on the backend to open the service page.
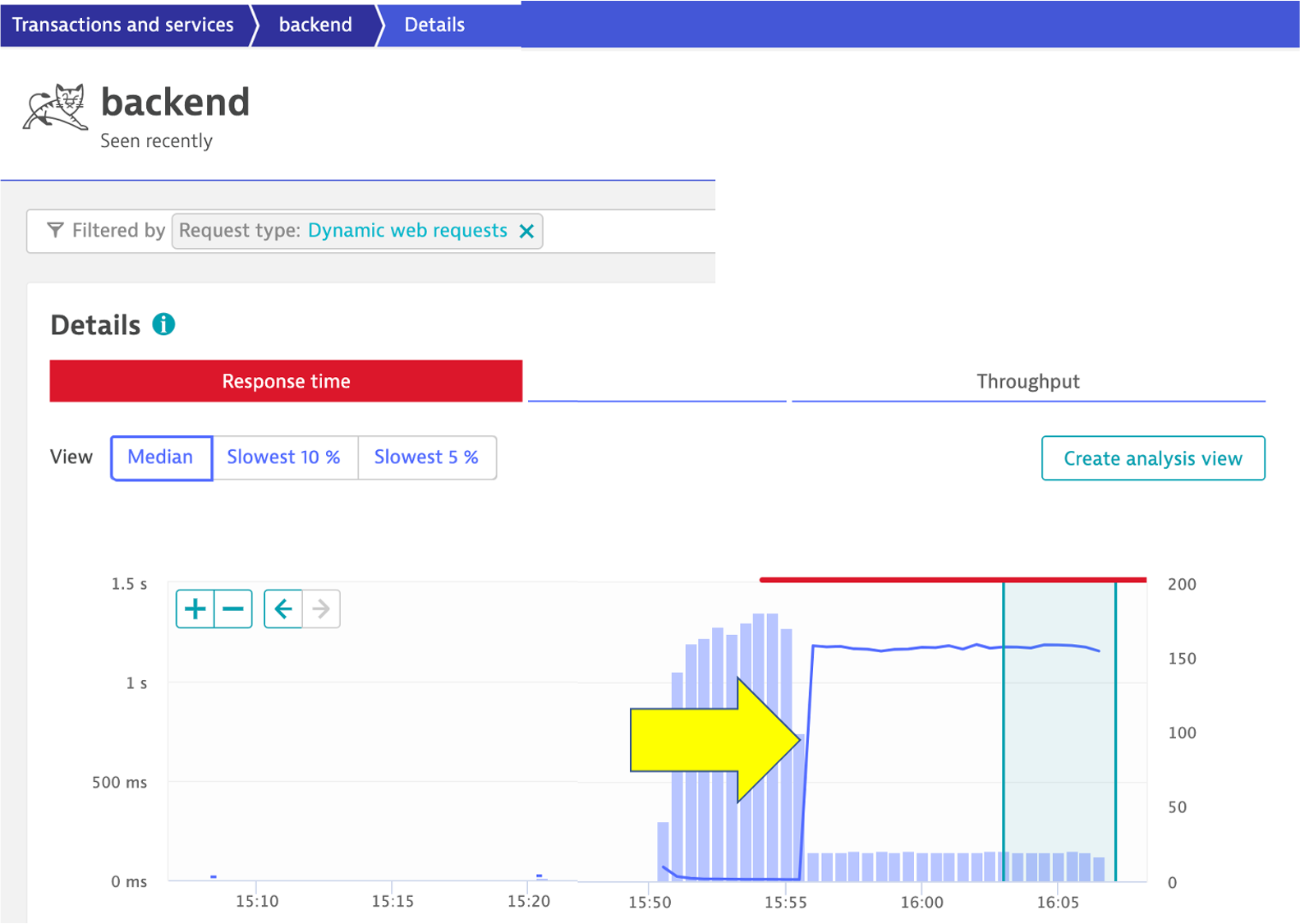
Then click on the response time box to open the service details page. You can see exactly when the problem started.
8. Disable the problem pattern
Run these commands to set the backend to version 1
cd ~/aws-modernization-dt-orders-setup/learner-scripts/
./set-version.sh backend 1
💥 TECHNICAL NOTE
Why does the problem card say ‘Custom Threshold'?
The Dynatrace AI engine is evaluating metrics and dependencies for daily and weekly traffic patterns. Since we just setup our sample application, there is not a lot of history to review we setup a fixed threshold as a global service setting.
To review this setting, on the left side menu, click settings, click Anomaly Detection and the the Services setting.
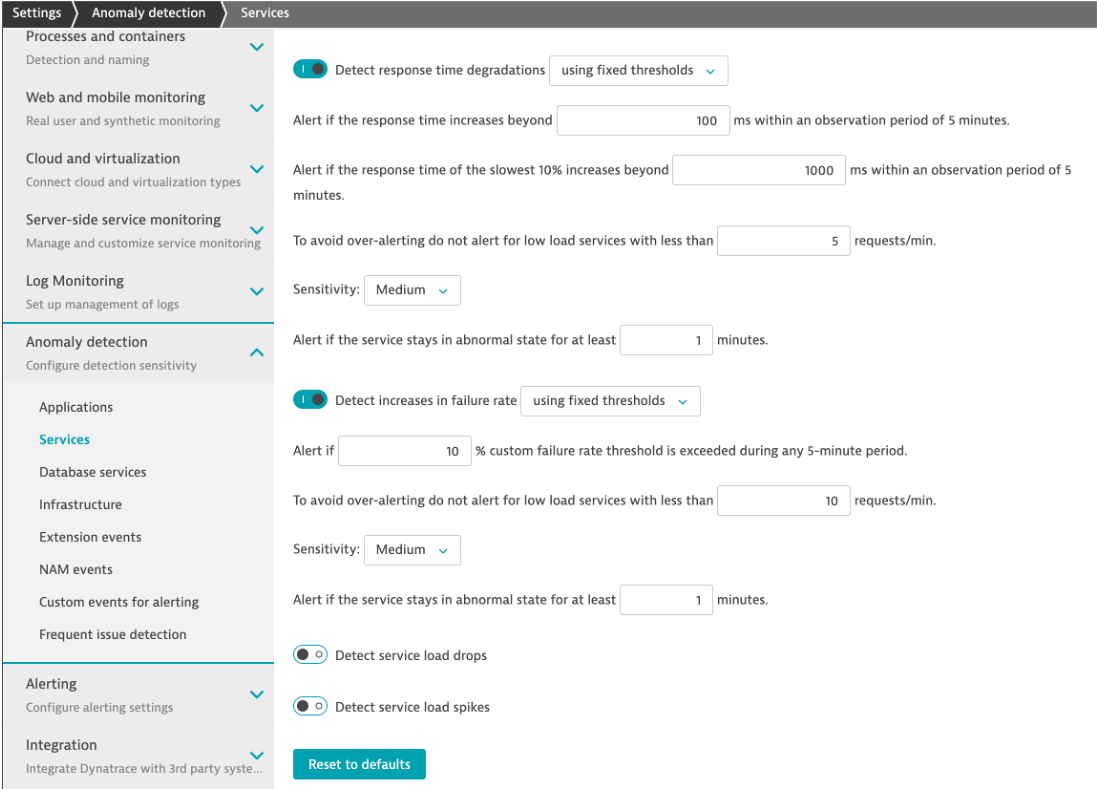
Learn more about how How problems are detected and analyzed in the Dynatrace Docs
Dynatrace will automatically close the problem once it detects things are back to normal.
In this section, you should have completed the following:
✅ Enable a problem in the application and walk through what Davis found